Pipeline Comparison
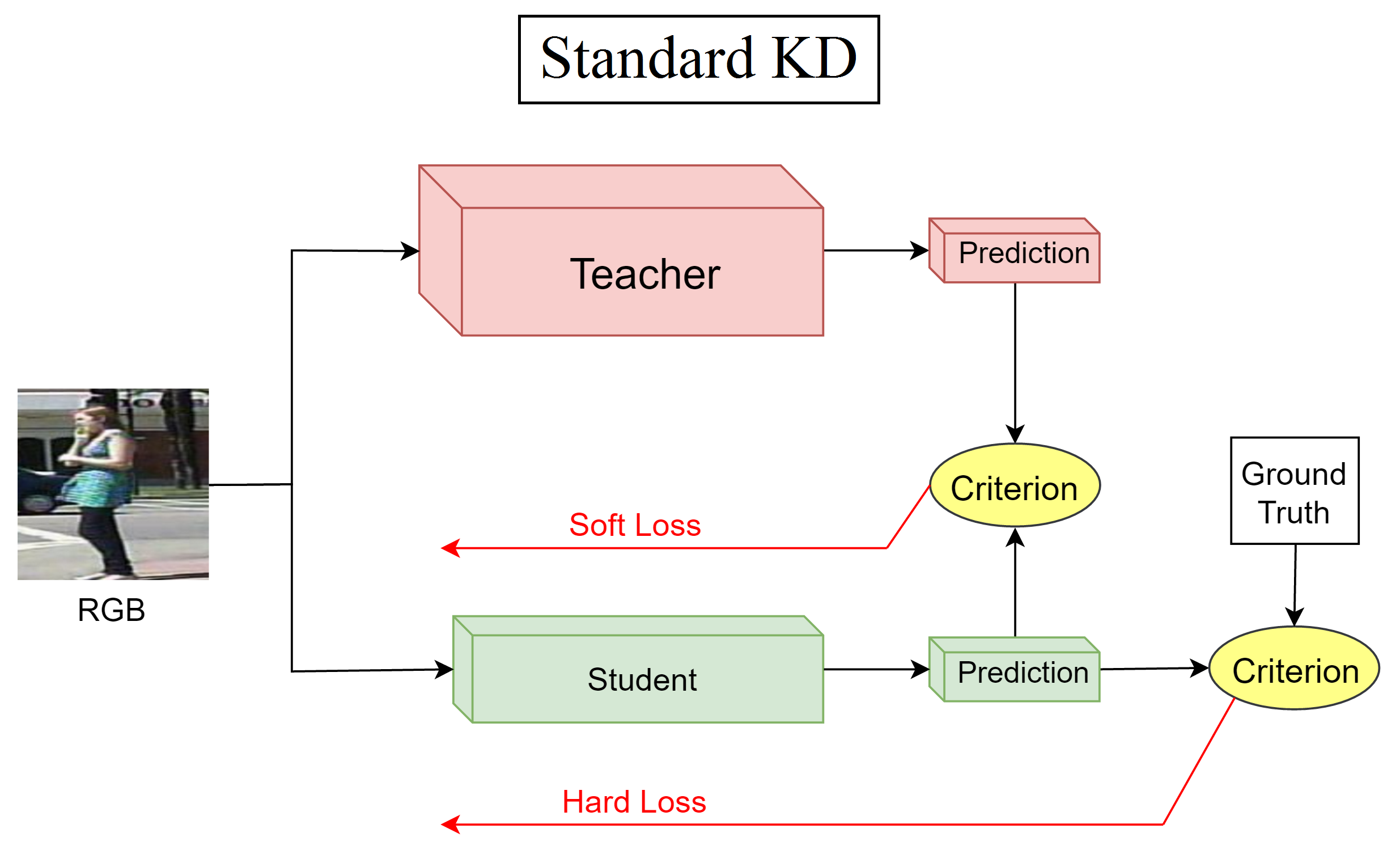
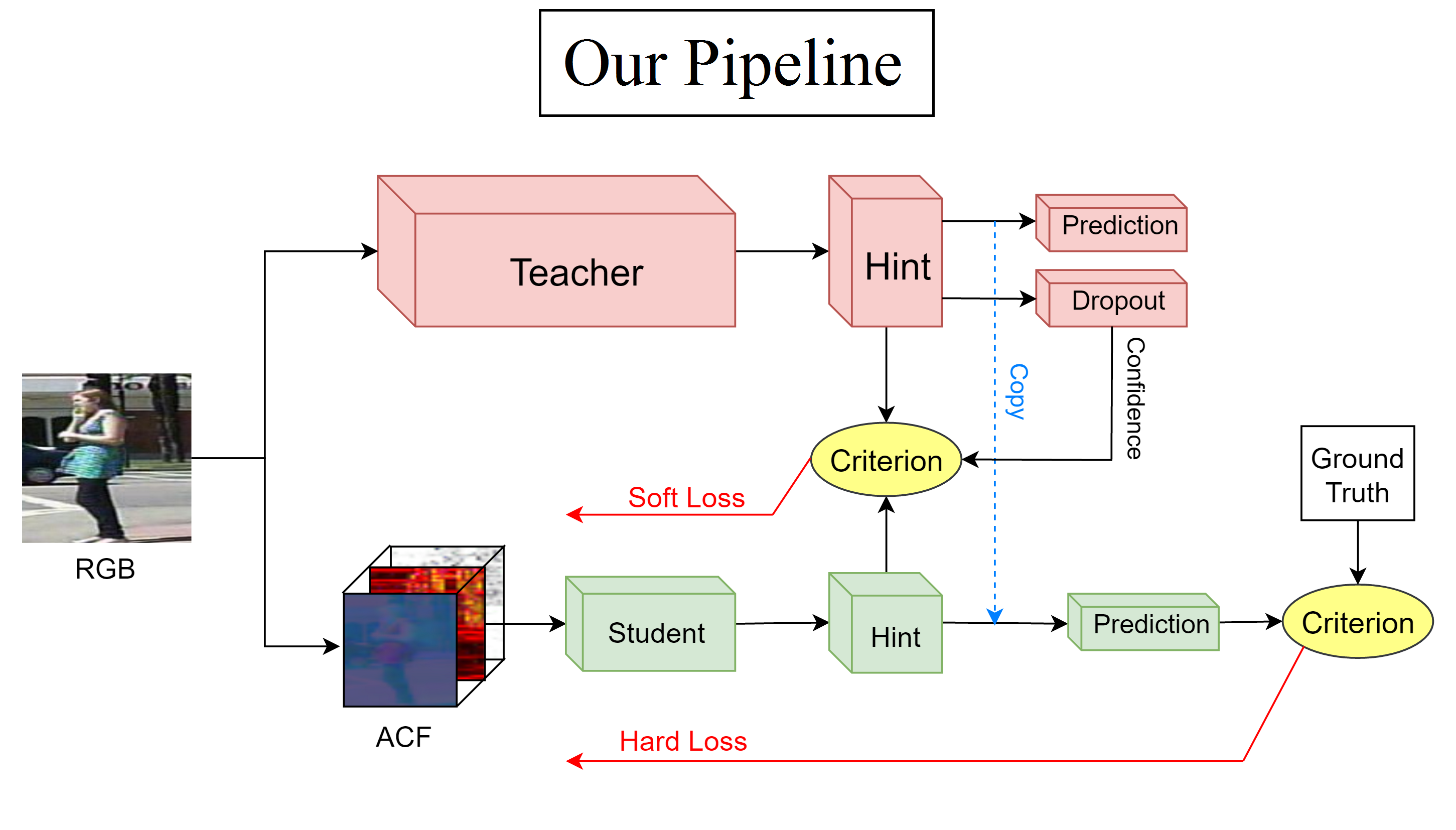
Results
| Models | Log-avg MR | Drop |
| Teacher | 17.5% | 0.0% |
| Student | 24.5% | 7.0% |
| Student+KD | 24.8% | 7.3% |
| Student+KD+Conf | 23.7% | 6.2% |
| Student+KD+Hint | 23.1% | 5.6% |
| Student+KD+Conf+Hint | 22.4% | 4.9% |
| Student+KD+ACF | 25.2% | 7.7% |
| Student+KD+ACF+Conf+Hint | 23.4% | 5.9% |
| Models | Params | Memory | Speed |
| ResNet-200 (Teacher) |
63 M | 4.93 GB | 24 ms |
| ResNet-18 | 11 M | 612 MB | 3 ms |
| ResNet-18-Thin | 2.8 M | 308 MB | 3 ms |
| ResNet-18-Small | 0.16 M | 240 MB | 3 ms |